In hashed tables, the main slot for a hash may be already used by keys with other hashes (not just because of collisions causing them to be chained to another free slot, but also because the size of the hash table is typically much smaller than the full set of possible hash values, for example when hash values are 32 bits, this does not mean that you need a hash table with 2^32 slots).
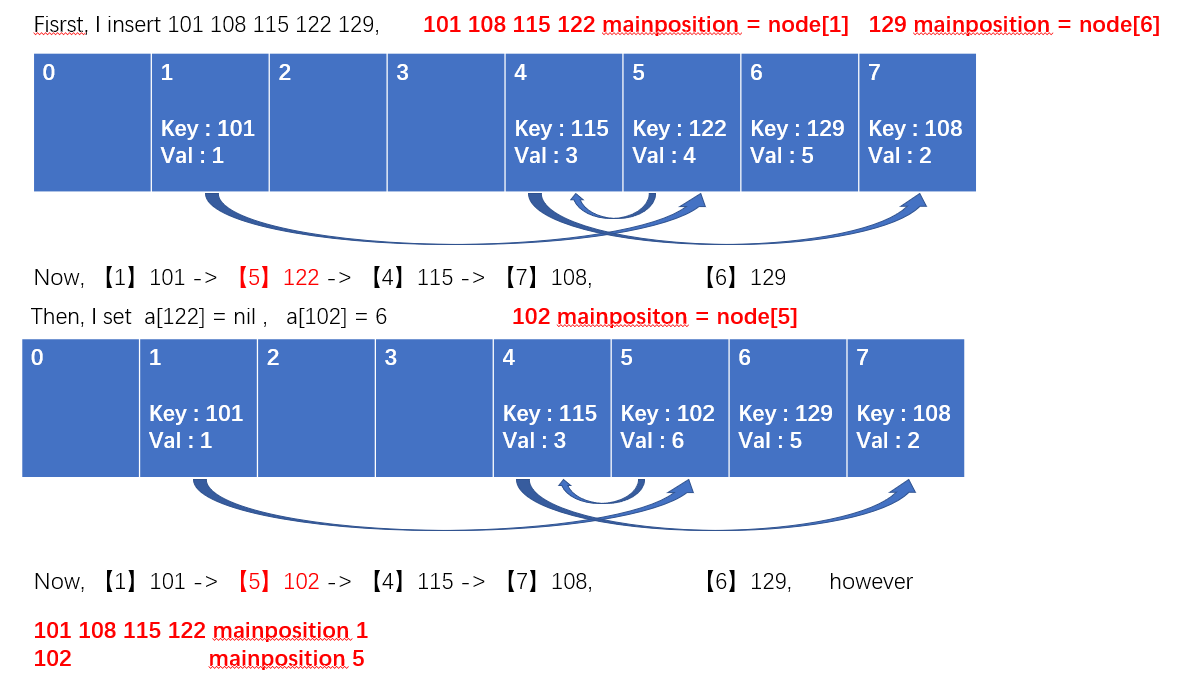
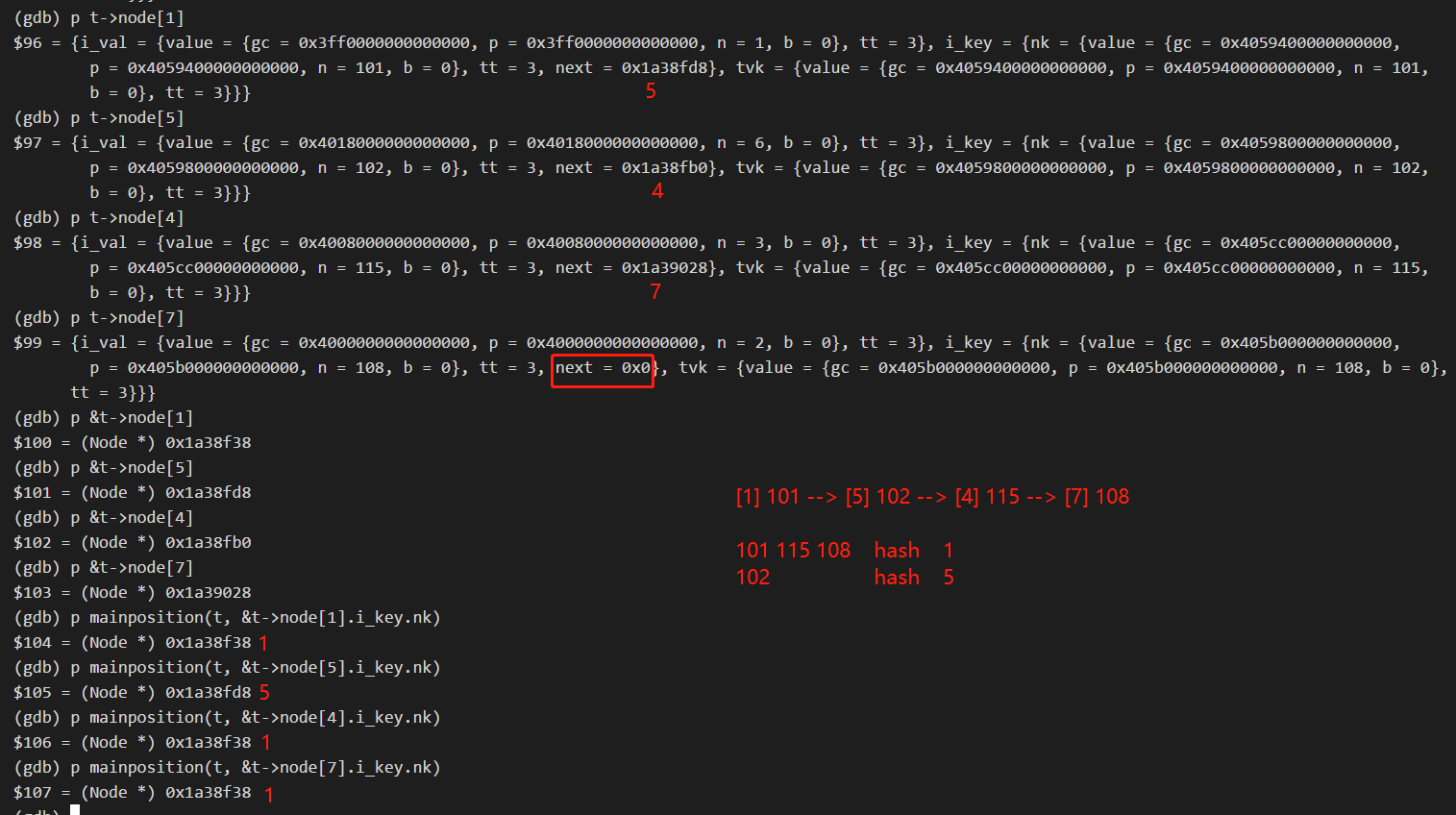
So it is legal (by definition) for the same chain of keys to link keys having different hashes: each time you browse items in the chain from a starting point, the key stored in that position is not necessarily the one you look for, so you need to compare the actual key to see if it matches, and if not continue visiting the chain until its end; if no keys are matched in the chain, then the key is not mapped in the table and the implicit associated value returned for it will be nil/null (and not "undefined" which is another non-nil/non-null value specifically used for declared variabled that were still unassigned: their key in the hash table is the variable name, or property name in objects).
When you set a key to null, the existing chain is not modified (it would require a table scan to find from which it is linked, or would require storing chains in two directions, i.e. would require storing two pointers per slot instead of one for the chains, in addition to the point to the key; such full table scan that would be needed would be very slow in large hash tables; typically the hash table structure maintains a counter of the used slots, which is incremented when a slot is allocated from a free slot: free slots can form their own chain where the value pointer is just nil/null to avoid table scans to find free slots; however when you reset the value associated to a key to null, the slot is NOT freed and its existing chaining pointers are preserved, to not break these chains).
There are different strategies possible:
- if the hash table is very small, performing a table scan when reseting a key's value to null/nil could be made in order to locate the allocated slot still referencing it in its chain and then update that other slot to skip over the "freed" slot.
- if the hash table is large, this is not acceptable (and using douly-linked chains would use too much memory: 4 pointers per slot (pointers to the key and to the value, and pointers for the forward chain and backward chains), instead of just 3 (omitting the backward chain).
- how pointers for chans are represented can be tuned: for small tables, you don't necessarily need a real pointer, just integer index for locating slots and if the hash size is small it could be a single 16-bit word, so that backward chains could be managed (this would reduce the frequency of collisions for distinct hashes at moderate fill level).
- for large tables, a "fill factor" threshold hint is used to determine when to reallocate a larger (or smaller) hash table (forcing keys to be rehashed and reloaded in new slot positions of the new hash table: here again, not all bits of the hash value are used, just a different number of bits, suitable for the hash table size). The fill factor thresholds (minimum and maximum) tend to be high for large tables, typically around 75% for the minimum and 85% for the maximum, but these threshold should be low for small hash table sizes (and the minimum threshold for very small tables could be safely 0% while the maximum at 50% would be fine).
I don't know if Lua has experimented in its implementation a way to manage the two thresholds for the fill factors at which a hashtable has to be reallocated and all keys in the associative table have to be rehashed (rehashing can be very slow in large tables). Or on a strategy allowing existing bits of hashes to be preserved (I've not seen successful experiments about such strategy).
But keep this in memory: an hash table always uses an optimistic where it is hoped that chains of collisions won't be very long. For this, it is critical that the hashing function (used to compute some bits from the actual keys) correctly distributes the keys.
What Lua has implemented however is segregating a part of the keys used by integer keys that form a "sequence" (keys from 1 to N, with very few holes in the middle): they are not stored in a hash with collision chains but in a simple vector where there can exist unused slots whose value pointer is nil/null, but where there's no chain pointers at all: access to these keys that are part of the sequence range is direct and does not require any hashing, but integer keys that fall outside the main sequence range are stored in the normal hash table (and those integers have then to be hashed). It is critical that the hashing function is correctly shuffling the bits of the key into a randomized set (simple hashing functions using multiplication by a small prime before adding the value of new bytes may not be good enough if the chosen prime is much smaller than the hash table; you may want to use a stronger hashing function like SHA-1 but it is generally much slower and could be costly to populate very large tables; using a good large prime multiplier is the correct strategy which is suitable for any hash table size which is not a multiple of that prime, in which case mapping an hash value to a slot index is simply stripping high bits, or computing a simple modulo if the hash table size is not a power of two)